


It all seems to be going pear shaped - rant, rant.
Maybe its the credit crunch finally starting to kick in but there seems to have been a rapid up-tick in the removal of freemium services, or worse still, a charge (now that's against the driving principle for me) starting to be applied.
Example that I have noticed this week - Google Reader (gone), Scoop-it shared curation (payment now required), LinkenIn book reader list (disappeared - along with all that bumph I wrote?).
All this puts a distinct shadow over 'cloud-based services' in my mind. In fact we don't really have a 'cloud' - as I've pointed out in previous blog's - what we have is a load of separate islands of adventure each with their own data store and application arrangements. Under total control of whoever runs the site. Sounds like a mainframe, operates like a mainframe, it is a mainframe - as they say.
So you get lured in on a cloud-like freemium offering and then once you have been locked in the squeeze is put on. Probably get this blog taken down now, just you see!
Some things you will probably think it worthwhile paying for others will fall by the wayside - what services do you really need? Don't give your data away without due consideration - that goes for companies too - you have been warned!
Why can't we build a proper cloud - rather than these islands - source data accessible by any means and not controlled by any one outfit - or is that a bit naive ;)
Saturday, 30 March 2013
Saturday, 23 March 2013
Compuplexity
Complex systems seem to be raising their head quite a bit these days - or is it just me noticing complexity now that I am into my MOOC!
Just had another example from my friend Ian from the BCS related to a paper on complex system failures - ref http://www.ctlab.org/documents/How%20Complex%20Systems%20Fail.pdf
What I have been thinking about is that the computer system I have been working on recently also falls into this complex system arena - see previous posts re-background. Some of the parallels are;
Given the paper referenced above - even simple changes can have big impacts!
More thought required.....
Just had another example from my friend Ian from the BCS related to a paper on complex system failures - ref http://www.ctlab.org/documents/How%20Complex%20Systems%20Fail.pdf
What I have been thinking about is that the computer system I have been working on recently also falls into this complex system arena - see previous posts re-background. Some of the parallels are;
- it is fundamentally composed of simple elements - spreadsheets (yuk) and simple calculation engines re used at the coal face,
- it has grown by the 'system' taking the good bits and improving upon them and killing of the parts that done work well - though there is a lot of old code still lying around!
- nobody really knows how it works - it just does
- people are by far the biggest element of the system and make it work despite it running with flaws
So according to my MOOC that would put it in the complexity box - and thats without considering fragmentation functions!
So now the question is how do you go about improving such a beast? Well thats the job really, but it isn't so straightforward a question to answer now that I have had a look in the box. The simple - helicopter - view is to just simply consider it a box. Lets just buy a better box! However, some critical things hang off the back end of the output from this box. So you had better not muck those up - or you are in jail!
Given the paper referenced above - even simple changes can have big impacts!
More thought required.....
Friday, 15 March 2013
Badge addiction!
I've registered on Foursquare - shock horror - have no idea why - got bored and was playing with it!
It reminds me of clocking on at the mill - yes I did work in a mill in a previous life - when we still had some in the UK that is!
However, I now have powers - I am the Mayor of the Travelodge Milton Keynes Central - wow! I can see how these badges become addictive. I'm going to try and become the mayor of my local ASDA next. Seeing as I seem to meet most of my work colleagues there doing the weekly Saturday shopping this could end up as a cross company Badge competition!
Its all a bit scary - you can see what others have been up to and others can see what you have been up to - useful for filling out your timesheet! Though I have discovered that connecting up with a work colleague that I wouldn't normally have much to do with has created an odd relationship. I know how he gets to work what he does for lunch and when he arrives home for the weekend. Is this a good thing - not entirely sure. There is something there, but it feels a little voyeuristic to be honest.
I can see that 'checking in' you could also meet up with new contacts - useful on a work front as well as social. I now feel obliged to check in at my mayoral residence(s) and I do feel sense of responsibility to these places weirdly!
Obviously something that needs a bit more investigation.....
It reminds me of clocking on at the mill - yes I did work in a mill in a previous life - when we still had some in the UK that is!
However, I now have powers - I am the Mayor of the Travelodge Milton Keynes Central - wow! I can see how these badges become addictive. I'm going to try and become the mayor of my local ASDA next. Seeing as I seem to meet most of my work colleagues there doing the weekly Saturday shopping this could end up as a cross company Badge competition!
Its all a bit scary - you can see what others have been up to and others can see what you have been up to - useful for filling out your timesheet! Though I have discovered that connecting up with a work colleague that I wouldn't normally have much to do with has created an odd relationship. I know how he gets to work what he does for lunch and when he arrives home for the weekend. Is this a good thing - not entirely sure. There is something there, but it feels a little voyeuristic to be honest.
I can see that 'checking in' you could also meet up with new contacts - useful on a work front as well as social. I now feel obliged to check in at my mayoral residence(s) and I do feel sense of responsibility to these places weirdly!
Obviously something that needs a bit more investigation.....
Sunday, 10 March 2013
Big Data and Fractals all in one post!
Data fragmentation was the topic of the last post - and this weeks meandering thoughts have also been on data fragmentation and measures of its complexity - now that is a bit of a mind bender - and whether the advent of Cloud Computing (aka mainframes) will help in sorting the fragmentation mess out?
The problem as I see it is everything starts with a plan of having a central 'Big Data' repository (aka Computing Centre) from which all decision making analysis can be driven. However, in reality - out in the field - individuals need some local, specific, analysis to be performed to help them do their job. So they take a data extract from the 'Big Data' and do what they need to do. The problem is, these extracts over time, can take on a life of their own, along with growth of all sorts of other associated ecosystems. This cycle of events can continue down to individual spreadsheet levels!
Aside: I have to come clean and confess that I have made extensive use of Excel (filter functions) this week - given my panning of Excel programming this does feel a little hypocritical - however - they have proven very useful - just illustrating the ease with which you can get drawn into this! Its not been real coding though - so I think I am still OK ;)
So, where is all this going? The question is, is it possible to measure the complexity of this fragmentation using some measure of the fractal dimension of the data sets - that's a thought from the MOOC course I'm taking! Can this be used to estimate the amount of effort required to consolidate the fragmented data? In fact, how do you calculate the dimension of a dataset? Will Cloud Computing help solve some of these problems going forward? The root cause of the fragmentation is people wanting something that corporate locked down system do not provide - will the new Cloud systems give people the freedom to build (under proper supervision) what they need locally or will it end up in this non-virtuous cycle again? What is the probability of the fragmentation occurring again?
Need to watch the next lecture on the course - maybe there is no connection!!
Obviously more questions than answers here - the revival continues ......
The problem as I see it is everything starts with a plan of having a central 'Big Data' repository (aka Computing Centre) from which all decision making analysis can be driven. However, in reality - out in the field - individuals need some local, specific, analysis to be performed to help them do their job. So they take a data extract from the 'Big Data' and do what they need to do. The problem is, these extracts over time, can take on a life of their own, along with growth of all sorts of other associated ecosystems. This cycle of events can continue down to individual spreadsheet levels!
Aside: I have to come clean and confess that I have made extensive use of Excel (filter functions) this week - given my panning of Excel programming this does feel a little hypocritical - however - they have proven very useful - just illustrating the ease with which you can get drawn into this! Its not been real coding though - so I think I am still OK ;)
So, where is all this going? The question is, is it possible to measure the complexity of this fragmentation using some measure of the fractal dimension of the data sets - that's a thought from the MOOC course I'm taking! Can this be used to estimate the amount of effort required to consolidate the fragmented data? In fact, how do you calculate the dimension of a dataset? Will Cloud Computing help solve some of these problems going forward? The root cause of the fragmentation is people wanting something that corporate locked down system do not provide - will the new Cloud systems give people the freedom to build (under proper supervision) what they need locally or will it end up in this non-virtuous cycle again? What is the probability of the fragmentation occurring again?
Need to watch the next lecture on the course - maybe there is no connection!!
Obviously more questions than answers here - the revival continues ......
Sunday, 3 March 2013
Big Data fragmentation function ....
Got involved in 'Big Data' type activities this week then some 'physics from the past' emerged out of random thought processes!
Big Data Project (BDP names withheld to protect the innocent) started with - this is the system diagram 'someone draws a big system diagram with loads of connections'. Holy smoke how am I going to get my head around this one was the overriding thought! We are talking about a massive company with massive data requirements - a definition of 'Big Data'. Data has been replicated, re-used, added to across geographic and functional boundaries not to mention individual personal modifications down at Excel (yuk, yuk, yuk) level.
BDP's goal is to try and specify the core functionality of all of this. Well, we have started to plug away at unpicking it using process maps, system diagrams and data flows, so the fog is starting to clear.
The question in my mind though was how did it all get into this position in the first place all of the above was done for the right reasons - to get the day job done. Each core data element seems to have spawned a few siblings which in turn have spawned more. It would be useful to know if there was some measure of the 'robustness' for each and every data repository and what has been their history?
Data store's exploding into many fragments which then exploded even further like a palm firework were the images in my mind. That bizarrely made a connection to my particle physics past! This seemed a bit like the tracks we used to trawl though from the JADE central detector - on night shifts - burned forever into my memory bank!
Which then led me on to thinking about fragmentation functions - essentially how you characterise the cascade of particles from the central annihilation - electron and positron in the JADE case.
In summary (ish);
"Fragmentation functions represent the probability for a parton to fragment into a particular hadron carrying a certain fraction of the parton's energy. Fragmentation functions incorporate the long distance, non-perturbative physics of the hadronization process in which the observed hadrons are formed from final state partons of the hard scattering process and, like structure functions, cannot be calculated in perturbative QCD, but can be evolved from a starting distribution at a defined energy scale. If the fragmentation functions are combined with the cross sections for the inclusive production of each parton type in the given physical process, predictions can be made for the scaled momentum, xp, spectra of final state hadrons. Small xp fragmentation is significantly affected by the coherence (destructive interference) of soft gluons, whilst scaling violation of the fragmentation function at large xp allows a measurement of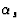 ."
."
(ref; http://ppewww.ph.gla.ac.uk/preprints/97/08/gla_hera/node5.html)
so now you know!
I'm sure the data we have now started off as 'Big Data' in some form prior to fragmentation so, is there an analogy between particle fragmentation and data fragmentation, and thus a means of potentially predicting fragmentation of new Big Data repositories within an organisation?
Oh well it was nice thinking about it anyway.....
Big Data Project (BDP names withheld to protect the innocent) started with - this is the system diagram 'someone draws a big system diagram with loads of connections'. Holy smoke how am I going to get my head around this one was the overriding thought! We are talking about a massive company with massive data requirements - a definition of 'Big Data'. Data has been replicated, re-used, added to across geographic and functional boundaries not to mention individual personal modifications down at Excel (yuk, yuk, yuk) level.
BDP's goal is to try and specify the core functionality of all of this. Well, we have started to plug away at unpicking it using process maps, system diagrams and data flows, so the fog is starting to clear.
The question in my mind though was how did it all get into this position in the first place all of the above was done for the right reasons - to get the day job done. Each core data element seems to have spawned a few siblings which in turn have spawned more. It would be useful to know if there was some measure of the 'robustness' for each and every data repository and what has been their history?
Data store's exploding into many fragments which then exploded even further like a palm firework were the images in my mind. That bizarrely made a connection to my particle physics past! This seemed a bit like the tracks we used to trawl though from the JADE central detector - on night shifts - burned forever into my memory bank!
Which then led me on to thinking about fragmentation functions - essentially how you characterise the cascade of particles from the central annihilation - electron and positron in the JADE case.
In summary (ish);
"Fragmentation functions represent the probability for a parton to fragment into a particular hadron carrying a certain fraction of the parton's energy. Fragmentation functions incorporate the long distance, non-perturbative physics of the hadronization process in which the observed hadrons are formed from final state partons of the hard scattering process and, like structure functions, cannot be calculated in perturbative QCD, but can be evolved from a starting distribution at a defined energy scale. If the fragmentation functions are combined with the cross sections for the inclusive production of each parton type in the given physical process, predictions can be made for the scaled momentum, xp, spectra of final state hadrons. Small xp fragmentation is significantly affected by the coherence (destructive interference) of soft gluons, whilst scaling violation of the fragmentation function at large xp allows a measurement of
(ref; http://ppewww.ph.gla.ac.uk/preprints/97/08/gla_hera/node5.html)
so now you know!
I'm sure the data we have now started off as 'Big Data' in some form prior to fragmentation so, is there an analogy between particle fragmentation and data fragmentation, and thus a means of potentially predicting fragmentation of new Big Data repositories within an organisation?
Oh well it was nice thinking about it anyway.....
Subscribe to:
Comments (Atom)